 |
||||||||||||||||||||
Начало пути Первое, что нужно определить – последовательность заполнения слов. Для этого имеются весьма простые и очевидные решения. Решение № 1: Слова будут генерироваться в последовательности, зависящей в первую очередь, от их длины. Чем длиннее слово, тем больше у него может быть пересечений и тем труднее будет найти слово для установки. Напротив, самые короткие слова, длиной в 2 или 3 буквы, будут иметь минимальное количество пересечений и их максимально удобно подбирать на завершающем этапе генерации. Данное решение используется на этапе анализа. Решение № 2: Из слов с одинаковой длиной, в первую очередь будут устанавливаться слова с наибольшей сложностью установки. Сложность установки – расчетный параметр, который показывает «насколько сложно будет подобрать значение в это слово» и «насколько большая будет цена ошибки, если слово подобрать не удастся». Понятно, что слова одинаковой длины, например, 5 букв, могут пересекаться как с одним словом, так и сразу с пятью, при этом сложность установки будет совершенно разная. Данное решение используется на этапе анализа. Решение № 3: C учетом предыдущих решений, слова у нас расположены в такой последовательности, которая не гарантирует пересечение двух соседних слов между собой. Это означает, что если мы не нашли слово для установки, тогда нужно изменить не предыдущее слово, а одно из ранее установленных слов, которые пересекаются с этим словом и по сути задают для него условия подбора. Логично из всех ранее установленных слов-пересечений, заменить слово, установленное последним, чтобы откатиться на минимальное количество слов генерации. Данное решение используется на этапе генерации. Фрагменты Если отследить установку слов в той последовательности, которая была определенна на основании решений № 1 и № 2, можно заметить, что установка некоторых слов образует локально независимые фрагменты. Посмотрите на рисунок ниже. 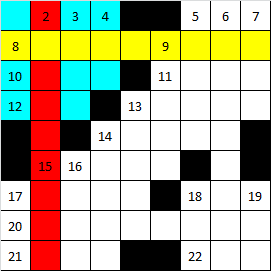 На рисунке цветами показана последовательность установки первых слов в сетку кроссворда в порядке, соответствующем известному «Каждый охотник желает знать, где сидит фазан». Первым будет установлено слово, помеченное красным. После него – слово, помеченное желтым и т.д. После установки всего 2-х слов в кроссворде образовался локальный фрагмент, помеченный голубым цветом. Прежде, чем продолжить, определимся сначала с терминологией:
При появлении фрагмента возникает дилема – либо продолжить генерацию кроссворда в ранее определенной последовательности, либо сгенерировать сначала все слова фрагмента, чтобы проверить правильность установки стартового слова. Это одно из мест алгоритма, которое может критически влиять на его общую производительность и которое не имеет четкого логического решения. Решение № 4: Для каждого устанавливаемого слова будет выполняться поиск фрагментов. Все слова, принадлежащие одному фрагменту будут иметь последовательную очередность установки, начиная от стартового слова, либо от первого слова фрагмента. Данное решение используется на этапе анализа. В данный момент, часть алгоритма по изменению последовательности генерации слов фрагментов выглядит следующим образом:
Собственно на этом все – алгоритм для генерации кроссворда обычным перебором готов. При минимальной детализации, выглядит он следующим образом:
Проверено – он реально работает на сетках до среднего уровня сложности. Однако, по мере усложнения сетки кроссворда и увеличении количества слов, количество удачных попыток генерации, стремится к 0. Собственно, с этого момента и начинается самое интересное…
|
||||||||||||||||||||