 |
||||||||||||||||||||||||||||||||||||||||
Шаблоны Первый вопрос, который приходит в голову – можно ли как-нибудь уменьшить количество откатов? Ведь каждый откат на несколько слов назад может стоить десятки и сотни тысяч итераций. Логически верным шагом становится добавление правил, которые уменьшают количество ошибок установки слов, вроде, не ставить мягкий или твердый знак в клетку, с которой начинается слово и т.д. Если не лезть глубоко, описать большинство этих правил для русского языка довольно просто, но есть проблема – они будут абсолютно бесполезны, например, для английского. Мне же хотелось сделать универсальный алгоритм, не зависящий от языка. Размышления над этим вопросом привели к следующему: «как было бы хорошо, чтобы для каждого еще неустановленного слова, пересекающего текущее устанавливаемое слово, было гарантировано наличие вариантов для установки». Так появилась идея использовать шаблоны, подобные команде LIKE в Transact-SQL. Шаблон – это символьная строка, по которой будет выполняться сравнение слов. Сам шаблон включает буквы и символы-шаблоны. Во время сравнения с шаблоном необходимо, чтобы буквы в точности совпадали с символами, указанными в строке. Символы-шаблоны могут совпадать с произвольными элементами символьной строки. Решение № 5: Для каждого стартового слова будут рассчитываться шаблоны всех пересекающихся с ним слов. Стартовое слово должно иметь буквы строго из списка в шаблоне, соответствующего позиции буквы пересечения. Данное решение используется на этапе генерации. Примеры шаблонов для слов из трех букв приведены ниже:
На примере последнего, читать шаблоны следует так: для слова из 3-х букв, у которого первые две буквы равны «ДО», в базе есть слова, у которых последняя буква равна одной из «Г К М Н». Акселераторы Вернемся снова к фрагментам. Посмотрите на рисунок ниже. В нем серым отмечены клетки слов, установленных ранее. При установке слова, помеченного красным, образуются сразу два фрагмента, отмеченных голубым и фиолетовым цветами. 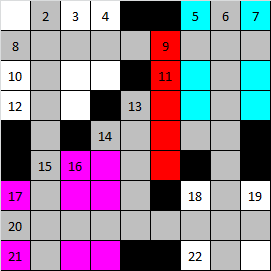 Если Вы посмотрите на фиолетовый фрагмент, то увидите, что он связан со стартовым словом одним единственным пересечением. И это прекрасно! Это дает нам возможность воспользоваться еще одним решением. Для начала, немного терминологии:
Решение № 6: При неудачной генерации фрагмента, для которого стартовое слово является акселератором, алгоритм будет хранить список букв, которые были установлены в стартовое слово на пересечении с одним из слов фрагмента для блокировки повторных установок слов, имеющих эти буквы на упомянутом пересечении. Данное решение используется на этапе генерации. Алгоритм использования акселераторов приведен ниже. Сначала – как это работает без акселератора:
Глубина фрагмента может быть достаточно большой и общее количество итераций для заполнения фрагмента может исчисляться миллионами. Для перебора всех возможных вариантов, нужно количество итераций для однократного заполнения фрагмента, умножить на количество слов в базе с длиной, как у стартового слова (которых могут быть десятки тысяч). Как это работает с акселератором:
Глубина фрагмента та же. Однако, для перебора всех возможных вариантов, нужно количество итераций для заполнения фрагмента умножить уже не на количество вариантов для стартового слова, а всего на 33 (количество букв в алфавите). Динамическая балансировка сложностью установки Предыдущие решения, по сути исчерпали те 20% усилий, которые, согласно принципу Парето, дают нам 80% результата. Далее приходится использовать все более сложные подходы, с порой неясными перспективами. Однажды, при генерации кроссворда, программа выдала такое сообщение: «Время полного перебора: 11 471 день …». Это сообщение появляется только в том случае, если был выполнен перебор всех вариантов для самого первого слова и требуется найти для него новое значение. Программа уже затраченное время просто умножает на оставшееся количество вариантов. Меня это позабавило и заставило задуматься, можно ли это время конвертировать в результат? Идея состоит в том, чтобы обдуманно обрезать некоторые варианты перебора, имеющие минимальную вероятностью успеха. Основной тезис этого решения – пусть лучше программа за минимально возможное время выдаст отрицательный результат (т.е. среди наиболее оптимальных вариантов подбор не удался), чем будет заниматься подбором столько времени, что будут превышены все мыслимые границы. Решение № 7: При установке слова, которое пересекают слова с большой сложность установки, запрещено ставить на позицию упомянутого пересечения буквы, частота применения которых в словах пересечениях минимальна. Данное решение используется на этапе генерации. Если по простому – это решение отбрасывает некоторое количество букв русского алфавита (иногда до 20), повышая шанс сгенерировать сложные участки из слов с чаще используемыми буквами (тут в шоколаде итальянский алфавит с его 21 буквой). В результате мы получим больше вариантов для подбора сложного в установке слова, когда до него дойдет очередь, а значит – больше шанс для успешной генерации всего кроссворда. Есть и минусы – часть вариантов перебора будет безвозвратно потеряна. Возможно, именно среди них будет тот самый, единственно возможный вариант заполнения сетки. Только Вы можете получить его через 30 лет – нужно лишь немного подождать… Еще одним минусом является то, что длинные слова, имеющие более 10 пересечений, сильнее всего и блокируются. Это приводит к тому, что программа не может начать генерацию, блокируя первое слово, пока для него не закончатся варианты. Обходится этот минус лишь частично, уменьшением степени блокировки, а значит и эффективности этого решения. Все, идеи закончились и пора переходить к тестированию…
|
||||||||||||||||||||||||||||||||||||||||